Same hook, 372x the views. Eye tracking shows where the gap opens.
Two creators opened with the same line ("Going viral didn't make me rich"). One put the caption above her face. The other put it across her face. Jeena ran both with real viewers to see how much that one decision cost.


Why I tested this
I saw the same hook twice in my feed. Same opening line ("Going viral didn't make me rich"), same proof structure, same kind of personal-revenue framing. Different creators. Hooks get lifted in short-form constantly, so that part was not surprising. What caught me was the gap. One had over a million views. The other had a few thousand.
Maybe the feed punishes duplicates, I thought. Maybe a second version of the same idea gets suppressed automatically. That would explain a hundred-to-one gap without me needing to look at the creative at all.
But the more I looked at the two videos, the less the algorithm story held up. Both creators sat in the same audience pocket. Production polish was comparable. The framework was the same. The thing I could not explain by squinting at thumbnails was why one held viewers and the other did not. So I opened Jeena and ran both through real-viewer eye tracking, because that is the one question a view count cannot answer: where exactly do the eyes go in the first second?
The setup
This topic lives or dies in the first seconds. The claim "Going viral didn't make me rich" is counterintuitive, so viewers decide quickly whether it is worth the effort to understand. The thing they need first is the face. Trust starts there. If something blocks the face in the opening frame, the viewer's gaze fights to find it, and that micro-conflict shows up later as a swipe.
Both creators leaned on the same core assets: a personal hook and social proof. The frameworks were similar. The visual language was similar. What I could not see without Jeena was where in each video the viewer's gaze actually went, and whether the curiosity bought by the hook survived the first beat.
What Jeena saw
The influencer
Caption above the face, polished talking-head
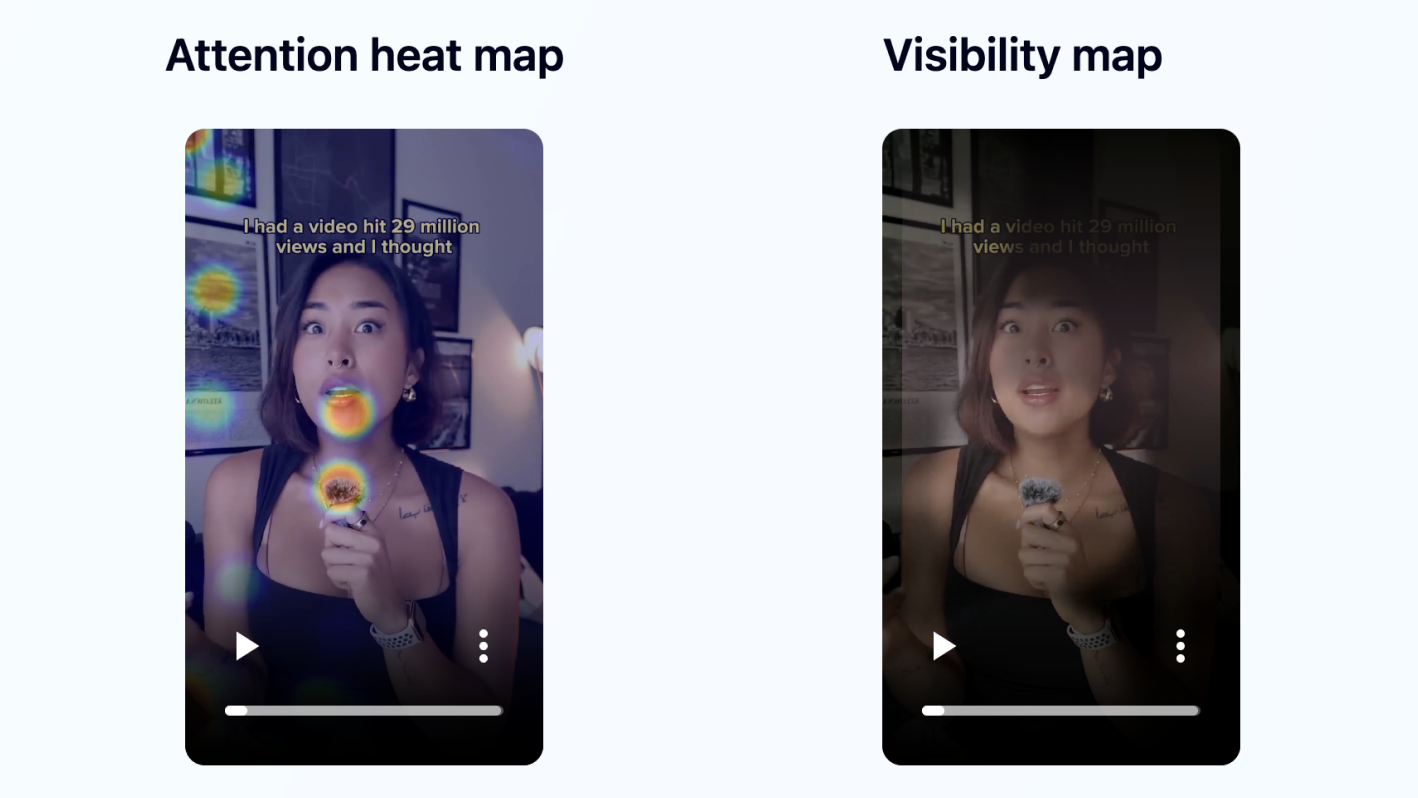
- •Counterintuitive opener with the yellow caption sitting above her head, face fully visible.
- •Polished talking-head delivery with readable captions throughout.
- •Credibility built through multiple proof assets (screenshots and a revenue graph).
- •Stepwise explanation that keeps the framework moving.
- •CTA-heavy ending that asks for action near the finish.
The copycat
Caption across the face, kinetic overlay
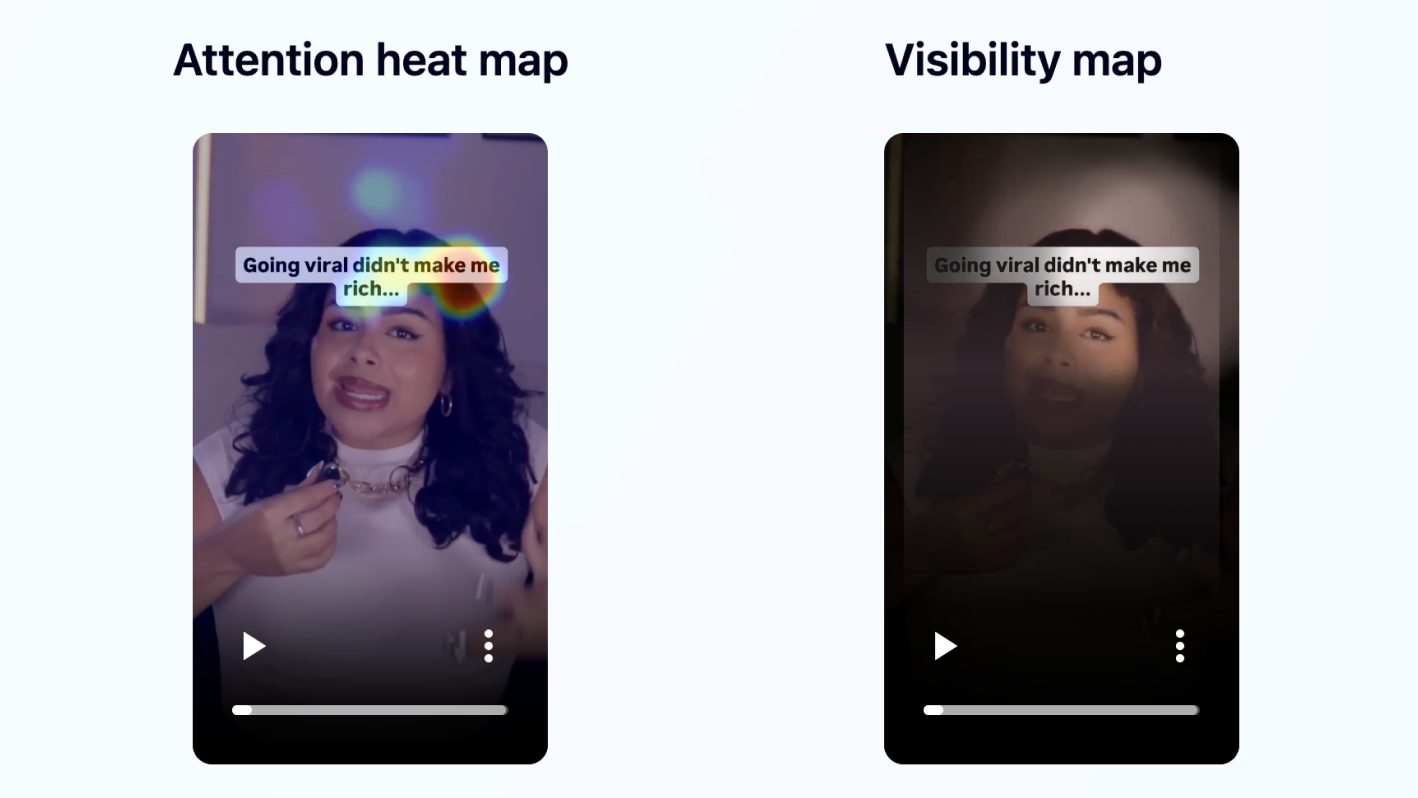
- •Counterintuitive opener with the caption bubble sitting across the forehead and upper face.
- •Credible proof insert early (1.2M views screenshot).
- •Clear, stepwise framework presented across a long middle.
- •Bold captioning with frequent emphasis on key phrases.
- •Ending lands on the word "Masterclass." rather than looping back to the opener.
You can see the divergence in the first frame
Look at the two hero portraits at the top of this article. Same hook. Same delivery format. Same kind of background.
The influencer's caption sits above her head. Her face is fully visible from the first frame, so the viewer's gaze can lock straight onto it. The copycat's caption sits across her forehead. The viewer's instinct is to look for the face, and the caption is in the way.
Jeena's eye tracking measured the cost of that one decision. A view count never could.
The hook was lifted. The first second was not.
The copycat had the same idea, the same proof type, the same framework. On every external dimension the two videos looked comparable.
Jeena's gaze data showed the split started in the opening frame. The influencer's viewers found the face immediately and stayed there for the hook. The copycat's viewers fought the caption for it, and the early gaze mismatch never fully recovered. By the middle, where her explanation runs long, attention had already started to drift. By the ending ("Masterclass.") the structure had nothing to loop back to.
A great hook gets lifted constantly. The defensible part is the next eight seconds, and the first of them is the face.
A great hook gets lifted constantly. The defensible part is the next eight seconds, and the first of them is the face.
Three creative choices that drove the split
Caption placement in the first second
Hook caption set above the head. Face fully visible from the first frame, gaze locks onto it immediately.
Hook caption bubble across the forehead and upper face. Viewers' gaze fights the caption to find the face.
Jeena's opening-frame gaze data showed a larger early mismatch on the copycat. The influencer's opener supported stronger face fixation and immediate credibility. Jeena's explicit recommendation on the copycat video was "move the hook caption to the lower-third."
Mid-roll cognitive load
Multiple proof segments with clean, scannable overlays across the middle.
A longer stretch of static explanation where on-device attention wandered more often.
The influencer held attention more consistently through the proof segment. The copycat's middle generated positive impressions on the survey side but the gaze track went off-screen more often. Jeena flagged the same fix on both: 2-to-3-second caption-synced micro pattern interrupts.
Ending strategy
CTA-heavy ending that drives toward conversion.
Ending closes on the word "Masterclass." without a visual return to the opener.
The influencer's structure produced stronger downstream actions (likes, comments, shares). The copycat's retention stayed variable to the end. Jeena recommended mirroring the opener's caption placement at the close so the algorithm's loop back to the start feels intentional.
What happened in the wild
| Influencer | Copycat | Δ | |
|---|---|---|---|
| Views | 1.1M | 3.0k | ×372 |
| Likes | 42.0k | 132 | ×318 |
| Comments | 25.9k | 11 | ×2354 |
| Shares | 13.5k | 20 | ×675 |
| Reposts | 340 | 6 | ×57 |
Three transferable principles for talking-head content
Do not let the hook caption sit over the speaker's face
Viewers will look away when a caption blocks eye-gaze, even if the idea is compelling. Jeena's recommendation on the copycat video was explicit: move the hook caption to the lower-third. The influencer kept the proof off the face and held more of the first-second attention because of it.
Convert long static explanation blocks into 2-to-3-second caption-synced micro pattern interrupts
Both videos showed attention drop-off through the middle. The fix is the same in both Jeena reports: whip-zoom, text-pop, or reverse-zoom synced to caption changes every 2 to 3 seconds. Static explanation reads as effort. Pattern interrupts read as motion.
A loop-friendly ending creates replay potential without a hard CTA
The influencer ended with a CTA stack; Jeena recommended swapping the stack for a replay-loop reprise of the opener with a flash of the same metrics card. The copycat's "Masterclass." ending could be fixed the same way: mirror the opener's caption placement so the cut back to the start looks intentional rather than abrupt.
What this means if you make these videos
If your hook is novel, it will be lifted. You cannot defend an idea in short-form. You can defend the first second of execution.
The influencer did not beat the copycat by having a better hook. She did not beat the copycat by having a better thesis. She beat the copycat by leaving her face uncovered in the first frame, by keeping the proof scannable through the middle, and by tying the ending back to the opener. None of those choices are expensive. All of them are decisions about where the viewer's eyes go in the first half of the video. And the only way to see those decisions land is to watch viewers watch.
Test your hook before you ship it
You can run this exact analysis on your own video. Upload it to Jeena. Real viewers watch it on their phones, with the front camera on, and share their impressions in a short survey. Jeena maps where their eyes went, when they raised their eyebrows, and which moments lost them. You get an attention heatmap, a visibility map, a wow-moments chart, a summary of how viewers perceived the video, and three concrete recommendations.
No "schedule a call." No sales rep. Upload, get your report.
Frequently asked
Why did the original outperform the copycat by 372 times?+
Both videos used the same hook ("Going viral didn't make me rich") with comparable production. Jeena's eye tracking shows the gap opened in the first frame: the copycat's opener caption sits across her face, while the influencer's sits above her head. The viewer's instinct in a talking-head opener is to find the face, and a caption on the face fights that instinct. The mismatch carried into a long static middle and an ending that closed on a flat statement rather than looping back to the opener. None of those choices were about the hook itself.
Can you protect a hook from being copied in short-form video?+
You cannot protect the idea. Hooks get lifted constantly, often within days, often by accounts at every audience size. What you can build is the first second of execution: caption placement that respects gaze, mid-roll pattern interrupts every 2 to 3 seconds, and a loop-friendly ending that mirrors the opener. The defensible part is the execution, not the hook.
Why is eye tracking the right tool for this question?+
A view count tells you the video underperformed. It cannot tell you where in the timeline the viewer gave up. Survey data tells you what viewers thought after they watched. It cannot tell you which frame their eyes were on when they swiped. The first-second face-versus-caption conflict in the copycat video is invisible to both. The only way to measure it is to watch viewers watch, frame by frame, which is what Jeena does with phone front-camera gaze tracking.
What is Jeena?+
Jeena is a neuromarketing platform for short-form video. Real people watch your video on their phone with the front camera on. Jeena captures their gaze direction, blink rate, eyebrow raises, and their impressions of the video in a short survey afterward. You receive an AI-powered report with an attention heatmap, a visibility map, a wow-moments chart, a summary of how viewers perceived the video, and three specific recommendations for making the video work harder.
How does Jeena measure viewer attention?+
Jeena uses smartphone front-camera gaze tracking. Each engager calibrates once, then watches your video. The platform records where their gaze lands frame by frame, flags moments of surprise from facial expression, and combines that with a short impressions survey afterward. The result is a per-second timeline of what real viewers actually looked at and felt, plus a summary of how they perceived the video overall.
Can I test my own video on Jeena?+
Yes. Sign up, upload your video, set a goal (Views, Sales, Pitch, Followers, and so on), and Jeena runs the test with its panel of engagers. The report typically arrives within a day, with an attention heatmap, a visibility map, a wow-moments chart, and three concrete creative recommendations.
How much does it cost?+
A typical test costs around ten euros. See the pricing page for current rates.